上篇博客从信号处理的角度解析了卷积计算和卷积神经网络中的卷积卷积操作。本文主要梳理一遍经典的卷积架构,如:ResNet,Inception架构,这些架构在CV任务上的表现十分出色,同时也给众多深度学习提供了新的思路,例如后来的DenseNet、ResNeXt等。以后有时间将扩展,偏功能的卷积架构有,在细粒度特征上可以采用SPPNet以及Few-shot learning 上的SiameseNet,图像分割中的FCN。本文将以LeNet简单介绍卷积基础架构开始,以讲述Blocks演变的形式简单讲解不同网络的特点。
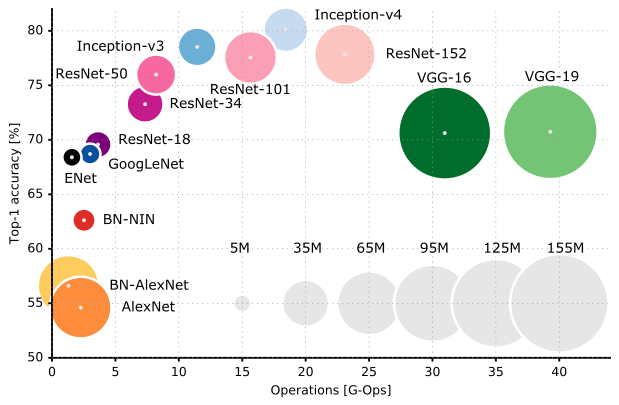
卷机神经网络基础架构
典型的神经网络由一个输入层,多个隐藏层和一个输出层组成,在卷积神经网络中称为全连接。对于每一层的输出:\(y_i=f(W_{i}x +b),其中f(x)为激活函数\);其经典结构如下图所示:
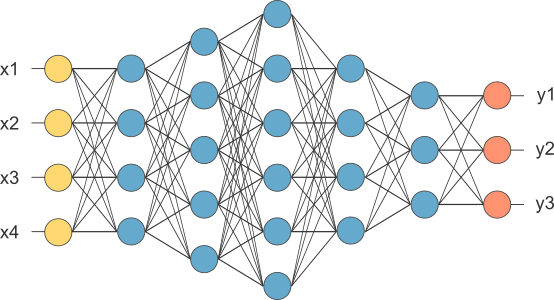
卷积神经网络的基础结构如下图所示:
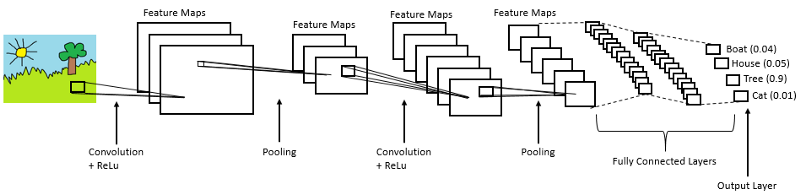
卷积神经网络采用的权值共享,相对与全连接操作,通常减少了数量级的参数;此外,卷积神经网络的局部操作,在处理具有局部相关性的任务时,与全连接相比具有明显的优势。
TODO:
卷积神经网络的构成成分:
- [x] 卷积层
- [x] 池化层
- [x] 全连接层(FCN和输出层前是Global_pooling的架构没有)
- 激活函数
- Batch Nomalization(BN层)
- 局部响应归一化(LRN)
- Dropout层
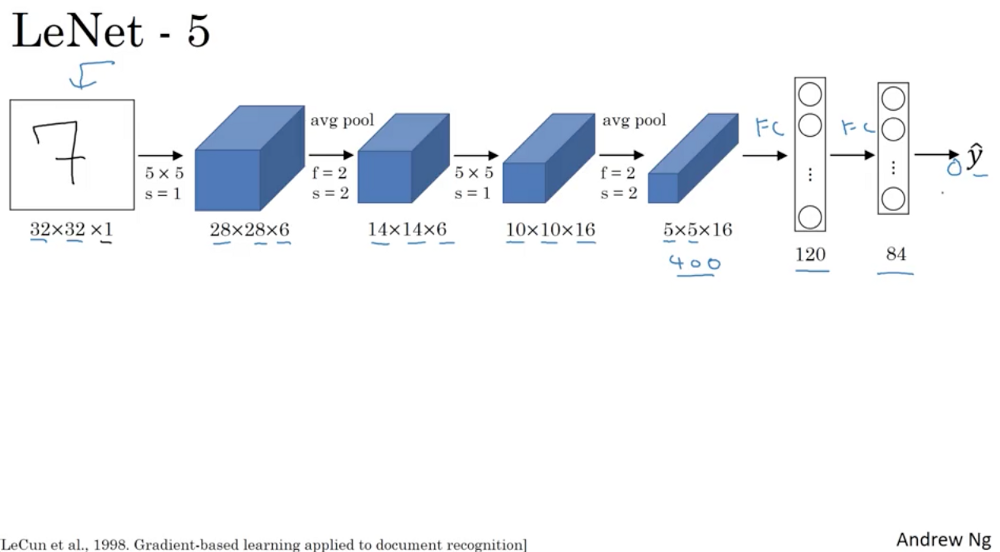
LeNet5
LeNet5架构是一个开创性的工作。图像特征是全局和局部的统一,LeNet5利用一组相同的卷积核在特征图的一个通道上对全局特征进行滤波处理,同时融合局部特征,利用下采样压缩局部的相似特征。当时没有GPU来帮助训练,甚至CPU速度都非常慢。因此,对比使用每个像素作为一个单独的输入的多层神经网络,LeNet5能够节省参数和计算是一个关键的优势。LeNet5论文中提到,全连接不应该被放在第一层,因为图像中有着高度的空间相关性,并利用图像各个像素作为单独的输入特征不会利用这些相关性。因此有了CNN的三个特性了:1.局部感知、2.平移不变性(下采样)、3.权值共享。
AlexNet
AlexNet特点:
- 由五层卷积和三层全连接组成,输入图像为三通道 224x224 大小,网络规模远大于 LeNet-5
- 使用了 ReLU 激活函数,提高了训练速度
- 使用了 Dropout,可以作为正则项防止过拟合,提升模型鲁棒性
- 加入了局部响应归一化(LRN)提高了精度
- 引入最大池化
- 在训练时使用了分组卷积操作(参见《卷积神经网络(上)》)
- 一些很好的训练技巧,包括数据增广、学习率策略、weight decay 等
AlexNet架构:
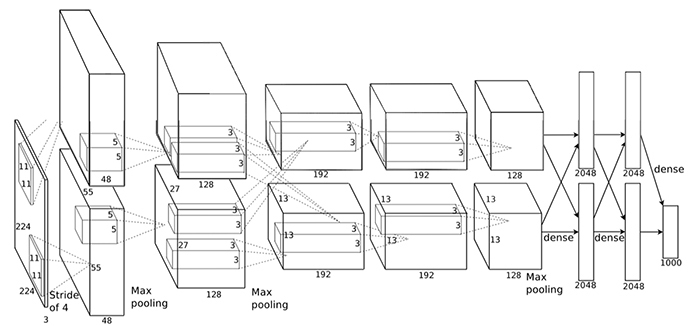
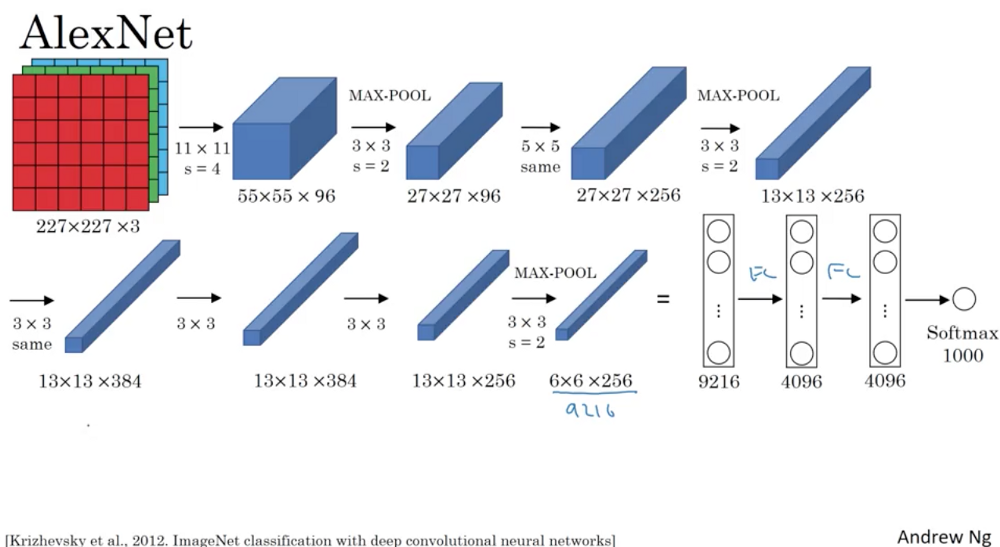
VGG
VGG是一种更简单的架构模型,因为它没有使用太多的超参数。它总是使用3 x 3滤波器,在卷积层中步长为1,并使用SAME填充在2 x 2池中,步长为2。
VGG使用3*3卷积核级联提高感受野,一改LeNet-5和AlexNet的
卷积-池化结构。VGG模型更深,参数更少,后续的模型基本都遵循了小卷积核级联的设计风格。
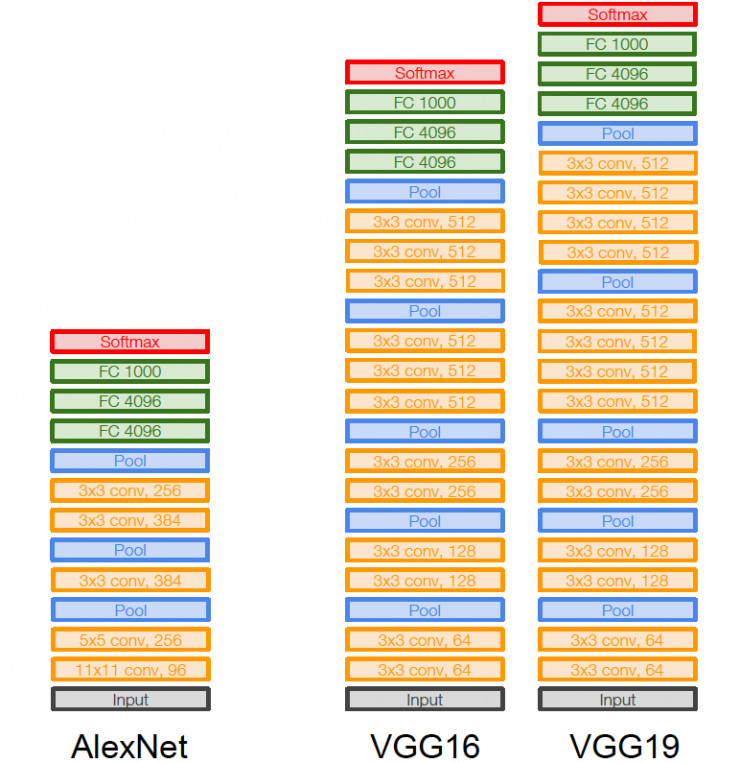
VGG
1 | # Keras API |
GoogLeNet
2014年ILSVRC的获胜者提出GoogLeNet架构也称为InceptionV1模型。它在具有不同感受野大小的并行路径中更深入,并且降低了Top5错误率到6.67%。该架构由22层深层组成。它将参数数量从6000万(AlexNet)减少到500万。GoogLeNet在使用了中间输出做了多任务学习,防止网络过深造成的梯度消失的情况;每层使用多个卷积核。
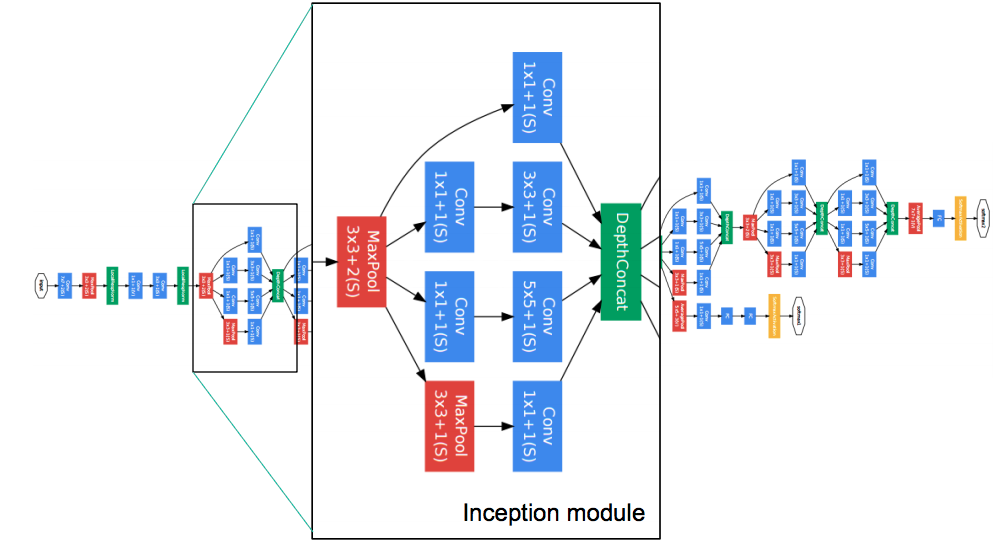
Inception V2
Iception V2 主要提出了Batch Nomalization(BN),BN层对mini-batch内部数据进行标准化,再给标准化数据乘以权重和加bias,保证了模型可以学习回原来的分布。用了BN层后减少或者取消 LRN。
- [ ] 后续有时间再写一个博客专门写深度学习的正则化, 可以关注深度学习中的Nomalization中的分析。
Inception V3
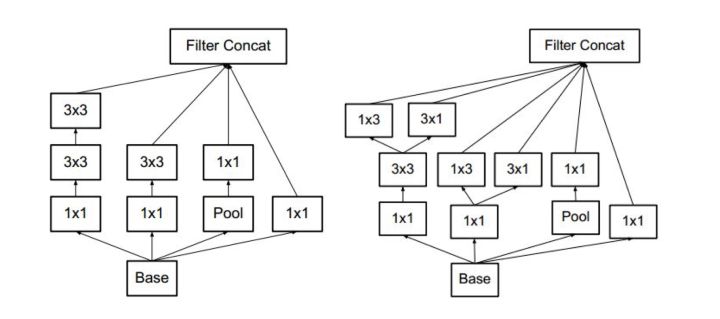
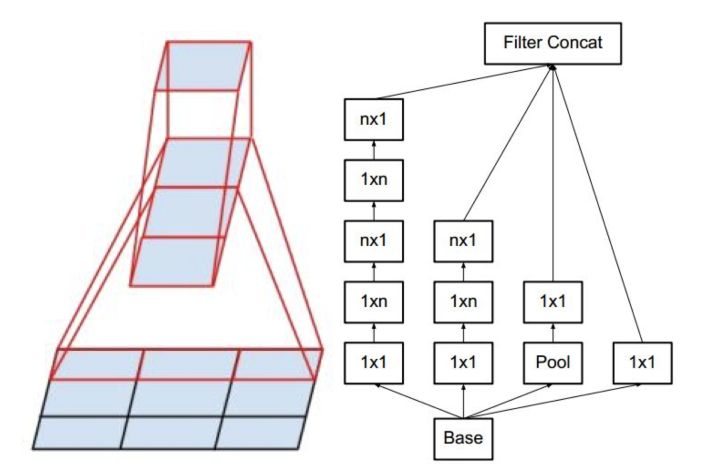
Inception V3将一个较大的二维卷积拆成两个较小的一维卷积,比如将7x7卷积拆成1x7卷积和7x1卷积,或者将3x3卷积拆成1x3卷积和3x1卷积,另外也使用了将5x5 用两个 3x3 卷积替换,7x7 用三个 3x3 卷积替换,如下图所示。一方面节约了大量参数,加速运算并减轻了过拟合,同时增加了一层非线性扩展模型表达能力。论文中指出,这种非对称的卷积结构拆分,其结果比对称地拆为几个相同的小卷积核效果更明显,可以处理更多、更丰富的空间特征,增加特征多样性。示意图如下:
ResNet
ILSRVC 2015的获胜者,被何凯明大神称为残差网络(ResNet)。该架构引入了一个名为“skip connections”的概念。ResNet采用Shortcut单元实现信息的跨层流通。与Inception 模块的Concat操作不同,Residual 模块使用 Add 操作完成信息融合。
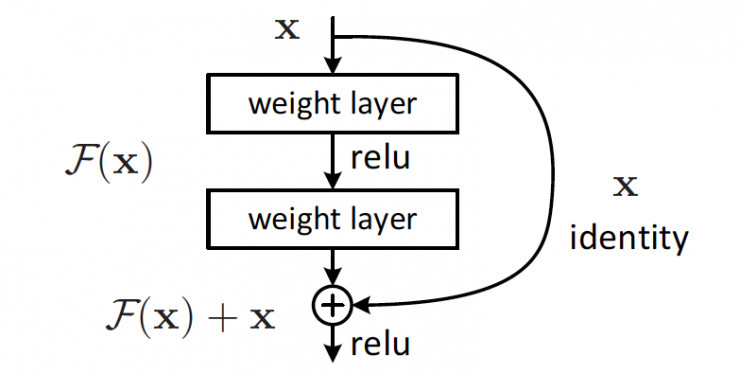
通过引入直连,原来需要学习完全的重构映射,从头创建输出,并不容易,而引入直连之后,只需要学习输出和原来输入的差值即可,绝对量变相对量,容易很多,所以叫残差网络。并且,通过引入残差,identity 恒等映射,相当于一个梯度高速通道,可以容易地训练避免梯度消失的问题,所以可以得到很深的网络,网络层数由 GoogLeNet 的 22 层到了ResNet的 152 层。然而,恒等函数与\(H_{\ ell}\)的输出是通过求和组合,这可能阻碍网络中的信息流。
keras_applications实现的Identity Block:
1 | def identity_block(input_tensor, kernel_size, filters, stage, block): |
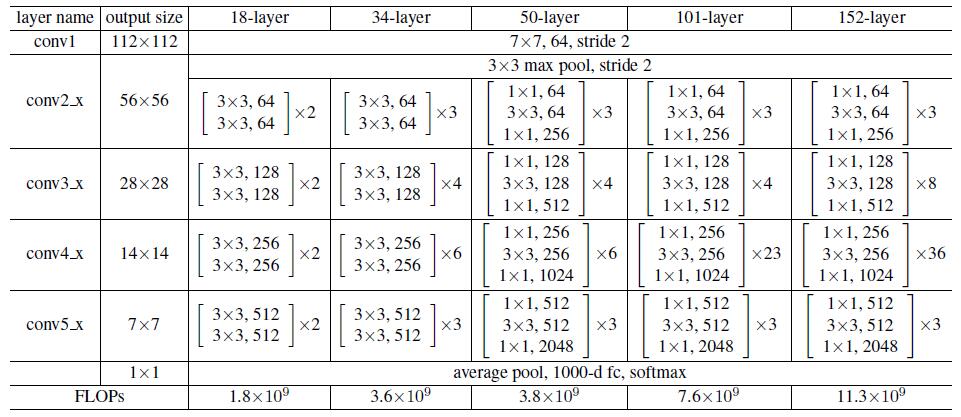
ResNet-34 的网络结构如下所示:
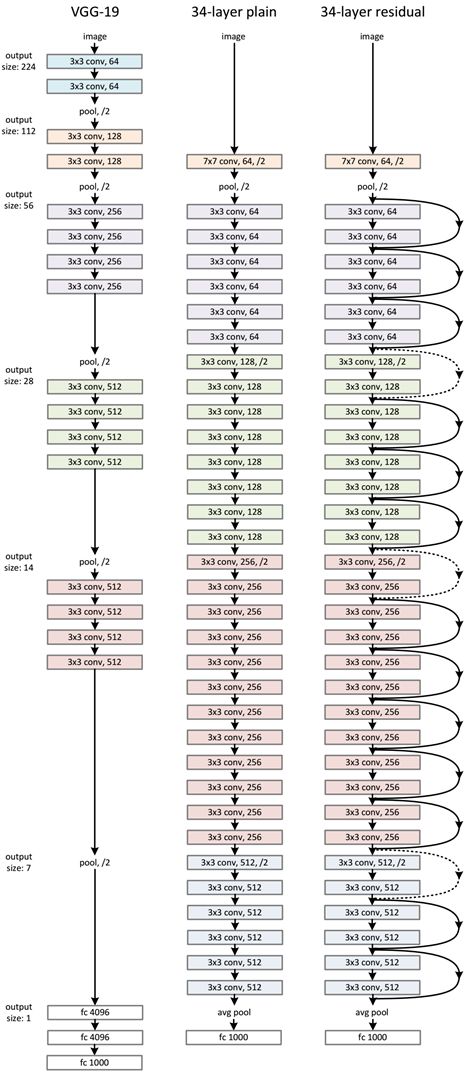
不同的ResNet结构对比:
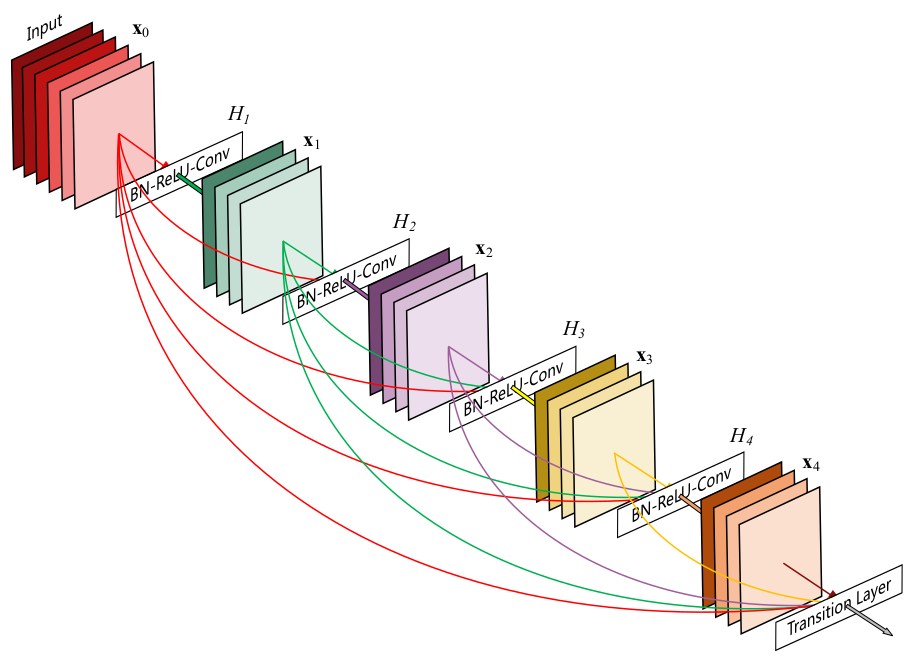
DenseNet
说到DenseNet全文就俩公式,当时我还觉得我咋写不出来这样的论文~~。
先预览下DenseNet论文里的DenseBlocks:
ResNet:传统的前馈卷积神经网络将第+1层的输入,可表示为:\(x_{\ell} = H_{\ell}(x_{\ell-1})\)。ResNet添加了一个跳连接,即使用恒等函数跳过非线性变换: \[ x_{\ell} = H_{\ell}(x_{\ell-1}) + x_{\ell-1} \]
密集连接:为了进一步改善层之间的信息流,我们提出了不同的连接模式:我们提出从任何层到所有后续层的直接连接。因此,第\(x_{0},…,x_{\ell-1}\)作为输入: \[ x_{\ell} = H_{\ell}([x_{0},x_{1},...,x_{\ell-1}]) \] 如果说Iception ResNet V2是Inception 思想融合了ResNet,那么我认为 DenseNet就是 Residual 思想(信息跨层流通)结合了Inception 理念。

DenseNet的几个重要参数:
增长率:如果每个\(H_{\ell}\)层输出K个特征图,那么第\(\ell\)层输出\(K_{0}+K(\ell-1)\)个特征图,其中\(K_{0}\)是输入层的通道数。
瓶颈层:即\(1\times1\)卷积层。每一层输出\(K_{0}+K(\ell-1)\)个,理论上将每个输出为个Feature Maps,理论上将每个Dense Block输出为K_{0}+_{1}^{}K(i-1)$个Fature Maps,。\(1\times1\)卷积层的作用是将一个Dense Block的特征图压缩到\(K_{0}+K\ell\)个。
压缩:为了进一步提高模型的紧凑性,我们可以在过渡层减少特征图的数量。。作者选择压缩率(theta)为0.5。包含Bottleneck Layer的叫DenseNet-B,包含压缩层的叫DenseNet-C,两者都包含的叫DenseNet-BC
1 | def dense_block(x, blocks, name): |
SENet
SENet(Squeeze-and-Excitation Networks)是基于特征通道之间的关系提出的,下图是SENet的Block单元,图中的Ftr是传统的卷积结构,X和U是Ftr的输入和输出,这些都是以往结构中已存在的。SENet增加的部分是U后的结构:对U先做一个Global Average Pooling(称为Squeeze过程),输出是一个1x1xC的数据,再经过两级全连接(称为Excitation过程),最后用sigmoid把输出限制到[0,1]的范围,把这个值作为scale再乘到U的C个通道上,作为下一级的输入数据。这种结构的原理是想通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
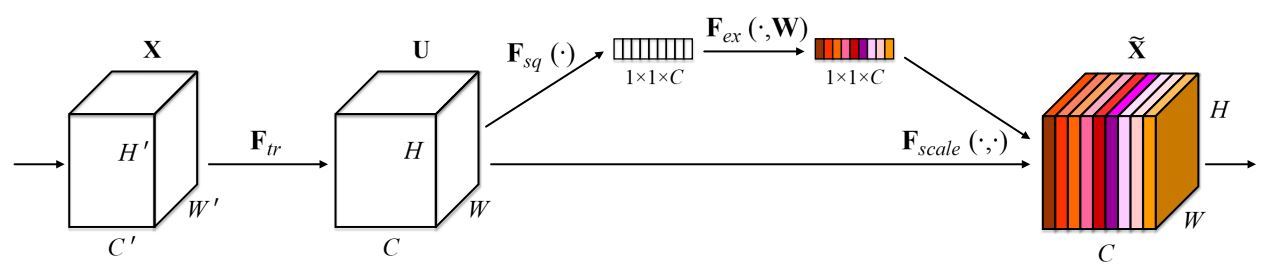
其实SENet就是通道级attention机制。
1 | def Squeeze_excitation_layer(self, input_x, out_dim, ratio, layer_name): |
总结:
卷积神经网络设计:
从防止梯度消失出发
从信息流通出发
从多尺度特征图融合出发
从通道级或者像素级特征选择出发
Reference
- LeNet
- AlexNet
- Network-in-network
- VGG
- GoogleNet
- Inception V3
- Batch-normalized
- ResNet
- Hu J, Shen L, Sun G. Squeeze-and-Excitation Networks[J]. 2017.
- https://chenzomi12.github.io/2016/12/13/CNN-Architectures/
