本章内容主要讲接下目标检测中的损失函数。目标检测的主要功能是定位和识别,损失函数的功能主要就是让定位更精确,识别准确率更高。其中常见的定位损失函数如MSE和Smooth L1,分类损失如交叉熵、softmax loss、logloss、focal loss等。目标分割是像素级的分割即每个点是什么都需要做一个识别的置信度评估,通常于分类相类似。
目标检测算法的损失函数
One-stage目标检测算法需要同时处理定位和识别的任务,即多任务,其损失函数通常是定位损失和分类损失的加权和。Two-stage的目标检测算法先定位ROI在进行分类操作。因此不管是One-stage还是Two-stage的目标检测算法都需要准确的定位和分类。
YOLO
在yolo上,输入图片被划分为7X7的网格,如下图所示:
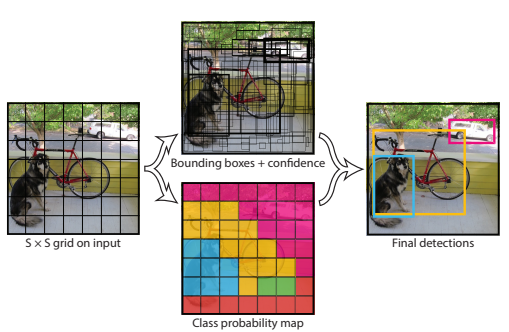
如上图所示,输入图片被划分为\(7 \times 7\)个单元格,每个单元格独立作检测。 在这里很容易被误导:每个网格单元的视野有限而且很可能只有局部特征,这样就很难理解yolo为何能检测比grid_cell大很多的物体。其实,yolo的做法并不是把每个单独的网格作为输入feed到模型,在inference的过程中,网格只是物体中心点位置的划分之用,并不是对图片进行切片,不会让网格脱离整体的关系。
可以通过yolo的structure来进一步理解,相比faster r-cnn那种two-stage复杂的网络结构而言,yolo的网络结构显得简单易理解。基本思想是这样:预测框的位置、大小和物体分类都通过CNN暴力predict出来。
yolo_v1的输出是一个\(7 \times 7 \times 30\)的张量,\(7 \times 7\)表示把输入图片划分位\(7 \times 7\)的网格,每一个小单元的另一个维度等于30即(2*5+20)。代表能预测2个框的5个参数(x,y,w,h,score)和20个种类。 \[ S\times S\times(B∗5+C) = 7\times7\times(2*5 + 20) \]
yolo的损失函数
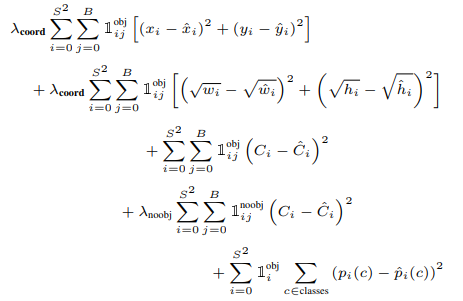
\(S^{2}\)表示网格数,在这里是\(7 \times 7\)。B表示每个单元格预测框的个数,这里是2。 第一行就总方误差( sum-squared error)来当作位置预测的损失函数,第二行用根号总方误差来当作宽度和高度的损失函数。第三行和第四行对置信度confidence也用MSE作为损失函数。第五行用MSE作类别概率的损失函数。最后将几个损失函数加到一起,当作yolo v1的损失函数。 \(l_{ij}^{obj}\)取值为0和1,即单元格内是否有目标。 \[λcoord = 5,λnoobj = 0.5 \]从上面公式也可以看得出来,yolo_v1就是选用最简单的MSE作为损失函数。
YOLO_V3的损失函数代码:
1 | xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[..., 0:2], |
Single Shot MultiBox Detector(SSD)
SSD的创新如下:
- 介绍了SSD,一种用于多种类别的单次探测器,比单次探测器(Yolo_v1)的先前技术更快,并且更加准确,实际上与执行显式区域提议的较慢技术一样准确和汇集(包括更快的R-CNN)。
- SSD的核心是使用应用于要素图的小卷积滤波器来预测固定的一组默认边界框的类别得分和框偏移。
- 为了获得高检测精度,我们从不同尺度的特征图产生不同尺度的预测,并通过纵横比明确地分开预测。
SSD的模型如下:
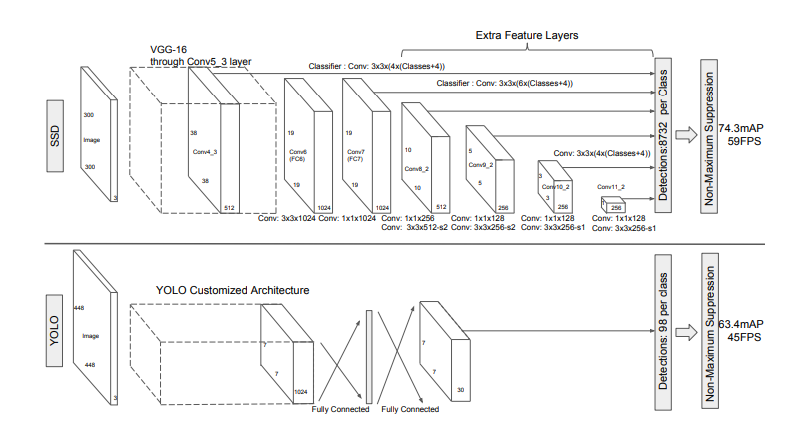
两个单发检测模型之间的比较:SSD和YOLO 。SSD模型在基础网络末端添加了几个要素图层,可以预测不同比例和宽高比的默认框的偏移量以及相关的置信度。具有\(300 \times200\)输入尺寸的SSD 在VOC2007 测试中的精度明显优于其\(448\times448\) YOLO同类产品,同时还提高了速度。
匹配策略:在训练过程中,我们需要确定哪些默认边界框对应实际边界框的检测,并相应地训练网络。对于每个实际边界框,我们从默认边界框中选择,这些框会在位置,长宽比和尺度上变化。我们首先将每个实际边界框与具有最好的Jaccard重叠(如MultiBox)的边界框相匹配。与MultiBox不同的是,我们将默认边界框匹配到Jaccard重叠高于阈值(0.5)的任何实际边界框。这简化了学习问题,允许网络为多个重叠的默认边界框预测高分,而不是要求它只挑选具有最大重叠的一个边界框。
训练目标函数:SSD训练目标函数来自于MultiBox目标,但扩展到处理多个目标类别。设\(x_{ij}^p = \lbrace 1,0 \rbrace\)是第i个默认边界框匹配到类别p的第j个实际边界框的指示器。在上面的匹配策略中,我们有\(\sum_i x_{ij}^p \geq 1\)。总体目标损失函数是定位损失(loc)和置信度损失(conf)的加权和: \[ L(x, c, l, g) = \frac{1}{N}(L_{conf}(x, c) + \alpha L_{loc}(x, l, g)) \tag{1} \] 其中N是匹配的默认边界框的数量。如果N=0,则将损失设为0。定位损失是预测框(l)与真实框(g)参数之间的Smooth L1损失。类似于Faster R-CNN,我们回归默认边界框(d)的中心偏移量(cx,cy,cx,cy)和其宽度(w)、高度(h)的偏移量。 \[ L_{loc}(x,l,g) = \sum_{i \in Pos}^N \sum_{m \in \lbrace cx, cy, w, h \rbrace} x_{ij}^k \mathtt{smooth}_{L1}(l_{i}^m - \hat{g}_j^m) \\ \hat{g}_j^{cx} = (g_j^{cx} - d_i^{cx}) / d_i^w \quad \quad \hat{g}_j^{cy} = (g_j^{cy} - d_i^{cy}) / d_i^h \\ \hat{g}_j^{w} = \log\Big(\frac{g_j^{w}}{d_i^w}\Big) \quad \quad \hat{g}_j^{h} = \log\Big(\frac{g_j^{h}}{d_i^h}\Big) \tag{2} \] Smooth L1: \[ smooth_{L_{1}}= \begin{cases} 0.5x^{2}\quad\quad if\quad |x| < 1\\\\ |x|-0.5\quad otherwise. \end{cases} \] 置信度损失是在多类别置信度(c)上的softmax损失。 \[ L_{conf}(x, c) = - \sum_{i\in Pos}^N x_{ij}^p log(\hat{c}_i^p) - \sum_{i\in Neg} log(\hat{c}_i^0)\quad \mathtt{where}\quad\hat{c}_i^p = \frac{\exp(c_i^p)}{\sum_p \exp(c_i^p)} \tag{3} \] 通过交叉验证权重项α设为1。
RetinaNet的focal loss
RetinaNet的作者分析出类别不平衡是导致 one-stage 检测方法精度不如 two-stage 的主要原因。
避免损失函数被 易分类的负样本 产生的损失湮没,注意 是 易分类的负样本
可以从以下两个方面解决
- 修改 正样本 和 负样本 对损失函数的贡献量,使二者平等
- 修改 难分类样本 和 易分类样本 对损失函数的贡献量,使二者平等
先看下经典的 交叉熵损失(cross entropy ): \[ CE(p,y)= \begin{cases} -log(p)\quad\quad if\quad y = 1\\\\ -log(1-p)\quad otherwise. \end{cases} \] 其中\(p\in[0,1]\)是模型预测类标签为1的概率(sigmoid函数),y是真实标签,其中\(y\in\{+1,-1\}\)。在文章中,作者简化写法如下: \[ p_{t}= \begin{cases} p\quad\quad if\quad y = 1\\\\ 1-p\quad otherwise. \end{cases} \] 其中\(CE(p,y)=CE(p_{t})=-log(p_{t})\)
为了解决正负样本不均衡的问题,在loss函数中引入参数\(\alpha_{t}\),如下: \[ CE(p_{t})=-\alpha_{t} log(p_{t}) \] 其中,对类标签为1的样本,\(\alpha_{t}=\alpha,\alpha\in[0,1]\),对类标签为-1的样本,\(\alpha_t = 1 - \alpha\)。
为了解决难易分类样本对loss函数权重贡献的问题,在loss函数中引入参数\(\gamma\) 和项\((1-p_{t})^\gamma\),自认为难分的样本容易被错分,常被错分的样本比较难分,对于易分样本,同理。Focal loss公式: \[ FL(p_{t})=-(1-p_{t})^\gamma log(p_{t}) \]
Fast RCNN
Fast RCNN的架构示意图如下:
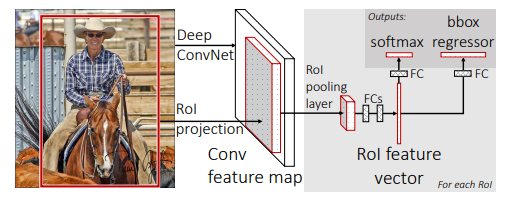
输入图像和多个感兴趣区域(RoI)被输入到全卷积网络中。每个RoI被池化到固定大小的特征图中,然后通过全连接层(FC)映射到特征向量。网络对于每个RoI具有两个输出向量:Softmax概率和每类检测框回归偏移量。该架构是使用多任务丢失端到端训练的。
Fast R-CNN网络将整个图像和一组候选框作为输入。网络首先使用几个卷积层(conv)和最大池化层来处理整个图像,以产生卷积特征图。然后,对于每个候选框,RoI池化层从特征图中提取固定长度的特征向量。每个特征向量被送入一系列全连接(fc)层中,其最终分支成两个同级输出层 :一个输出K个类别加上1个背景类别的Softmax概率估计,另一个为K个类别的每一个类别输出四个实数值。每组4个值表示K个类别的一个类别的检测框位置的修正。
Fast RCNN的损失函数:
Fast R-CNN网络具有两个同级输出层。 第一个输出在K+1个类别上的离散概率分布(每个RoI),\(p=(p0,…,pK)\)。 通常,通过全连接层的K+1个输出上的Softmax来计算p。第二个输出层输出检测框回归偏移,\(t^k = (t^k_x, t^k_y, t^k_w, t^k_h)\),对于由k索引的K个类别中的每一个。
每个训练的RoI用类真值\(u\)和检测框回归目标真值\(v\)标记。我们对每个标记的RoI使用多任务损失\(L\)以联合训练分类和检测框回归: \[ L(p, u, t^u, v) = L_{cls}(p, u) + \lambda \lbrack u \ge 1 \rbrack L_{loc}(t^u, v) \tag{1} \] 其中\(L_{cls}(p, u) = -\log p_u\), 是类真值\(u\)的log损失。
对于类真值\(u\),第二个损失\(L_{loc}\)是定义在检测框回归目标真值元组\(u, v = (v_x, v_y, v_w, v_h)\)和预测元组\(t^u = (t^u_x, t^u_y, t^u_w, t^u_h)\)上的损失。 括号指示函数\([u≥1]\)当\([u≥1]\)的时候为值1,否则为0。按照惯例,背景类标记为\(u=0\)。对于背景RoI,没有检测框真值的概念,因此\(L_{loc}\)被忽略。对于检测框回归,我们使用Smooth L1: \[ L_{loc}(t^u, v) = \sum_{i \in \lbrace x, y, w, h \rbrace}smooth_{L_1}(t^u_i - v_i) \tag{2} \] Smooth L1是鲁棒性的\(L_{1}\)损失,对于异常值比在R-CNN和SPPnet中使用的MSE损失更不敏感。当回归目标无界时,具有MSE损失的训练可能需要仔细调整学习速率,以防止爆炸梯度。公式(2)消除了这种灵敏度。
